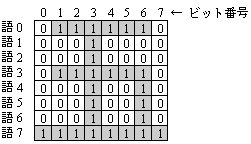
図1 ビット行列が描く図形の例
問1 ビット行列に関する次の記述を読んで,設問1〜4に答えよ。
1語8ビットからなる連続する8語(ビット番号0 が上位)を 8 × 8 のビット行列とみなすと,0と1のビットによって,図1に示すように図形を描くことができる。
図1 ビット行列が描く図形の例
設問1 図1の図形を描いたとき,語3の内容の16進表記として正しい答えを,解答群の中から選べ。
解答群
ア 10 イ 12 ウ 7E エ 80
オ 89 カ F9 キ FF
設問2 図1の図形を時計回りに 90°回転させた図形を描くように,語0〜7の内容を設定したい。このとき,語3に設定する値の16進表記として正しい答えを,解答群の中から選べ。
解答群
ア 01 イ 80 ウ 89 エ 91
オ 9F カ F9 キ FF
設問3 図1に示す図形を,直線Aを対称軸として対称移動した(裏返した)図形を描くと図2のようになる。
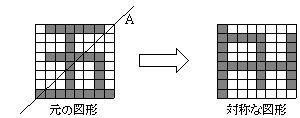
図2 直線A
を対称軸として対称移動した図形の例
語0〜7の内容が図3 のとおりになっているとき,このビット行列が描く図形を図2 のように対称移動した図形のビット行列を,語0〜7に設定したい。このとき,語3に設定する値の16進表記として正しい答えを,解答群の中から選べ。
|
語 0 |
7C |
|
語 1 |
42 |
|
語 2 |
42 |
|
語 3 |
7C |
|
語 4 |
50 |
|
語 5 |
48 |
|
語 6 |
44 |
|
語 7 |
42 |
解答群
ア 09 イ 19 ウ 29 エ 49 オ 90
カ 92 キ 94 ク 98 ケ FF
設問4 次の記述中の  に入れる正しい答えを,解答群の中から選べ。
に入れる正しい答えを,解答群の中から選べ。
1語nビットからなる連続したn語が描く図形を,図2のように対称移動した場合,元の図形のi語目の第jビットは,新しい図形の  語目の第
語目の第  ビットとなる(0 ≦ i ≦ n−1,0 ≦ j ≦
n−1)。
ビットとなる(0 ≦ i ≦ n−1,0 ≦ j ≦
n−1)。
解答群
ア n−i イ n−i−1 ウ n−i+1
エ n−j オ n−j−1 カ n−j+1
問2 次のプログラムの説明を読んで,設問1〜3に答えよ。
〔プログラムの説明〕
テキストエディタを実現するプログラムである。
(1) このプログラムが扱うことができるテキストは,1行は80文字まで,行数は MAX までである。
(2) 行の操作用に次の大域変数を定義する。
① CP: 処理の対象となる行を指し示す変数。
(3) 行の操作用に次の副プログラムを定義する。
① INSERT(x): 新たな行xを,CPが指し示す行に挿入する。挿入によって,元の行以降は1行ずつ繰り下がる。
② DELETE(): CPが指し示す行を削除する。削除によって,次の行以降は 1行ずつ繰り上がる。
③ LAST(): 最後の行の行番号(テキストの行数)を返す。テキストが空の場合は0を返す。
④ GET(): CPが指し示す行の文字列を返す。
(4) その他,CPの操作などのために,複数の副プログラムが定義されている。
設問1 文字列型の配列 LINE[i](i=1,2,… ,MAX)と,整数型の変数 TAIL を用いてプログラムを作成した。 i行目の文字列
Li は LINE[i] に格納し,変数TAIL には常に最後の行に対応した配列要素番号(空の場合は0)を格納する。
変数CP
の内容は,処理の対象となる行を格納した配列要素番号である。行数に関係なく,計算量(オーダ)を一定にすることが可能な副プログラムを,解答群の中からすべて選べ。
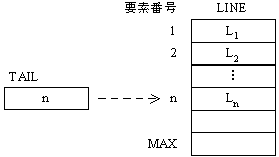
図1 配列を用いた実現例
解答群
ア DELETE() イ GET() ウ INSERT(x) エ LAST()
設問2
図2のように,ポインタを用いた双方向リストで実現するようにプログラムを変更した。リストの第i要素は,i−1行目を格納した要素へのポインタ, i 行目の文字列
Li ,i+1行目を格納した要素へのポインタで構成される。対象となる要素がない場合には,ポインタの値として0が格納される。
変数
HEAD は1行目を格納した要素を,変数TAILは最後の行を格納した要素を指し示すポインタである。
変数CPは,処理の対象となる行を格納した要素へのポインタである。行数に関係なく,計算量(オーダ)を一定にすることが可能な副プログラムを,解答群の中からすべて選べ。
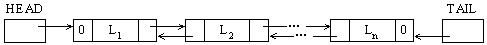
図2 ポインタを用いた実現例
解答群
ア DELETE() イ GET() ウ INSERT(x) エ LAST()
設問3 次の記述中の  に入れる正しい答えを,解答群の中から選べ。
に入れる正しい答えを,解答群の中から選べ。
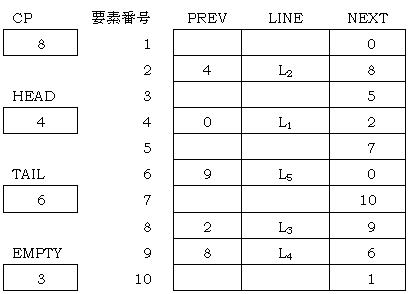
ポインタを用いる双方向リストを,三つの配列を用いて実現した。図3は,最大行数が10の場合の例である。変数CP には処理の対象となる行を格納した配列要素番号が,変数HEAD には最初の行を格納した配列要素番号が,変数TAIL には最後の行を格納した配列要素番号が,変数EMPTY には空リストの先頭の配列要素番号が格納されている。
行 L1,L2,L3,L4,
L5が図3の状態で格納されていて,CP=8 のとき, DELETE()を実行して行
L3を含んだ配列要素を削除すると, HEAD と TAIL の値には変更がなく,EMPTY=8,PREV[9] =  ,NEXT[2] = , NEXT[8] =
,NEXT[2] = , NEXT[8] =  となる。ここで,削除された配列要素は,空リストの先頭に追加するものとする。
となる。ここで,削除された配列要素は,空リストの先頭に追加するものとする。
解答群
ア 0 イ 1 ウ 2 エ 3
オ 7 カ 8 キ 9 ク 10
問3 関係データベースに関する次の記述を読んで,設問1,2に答えよ。
次の受注伝票をもとに関係データベースを構成する表を作成し, SQL を利用してデータを検索することを考える。
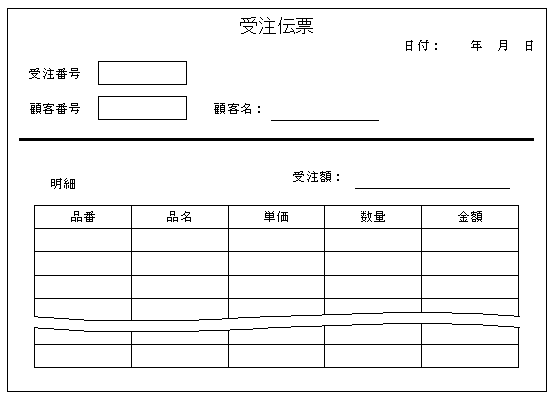
注 1件の受注は1枚の受注伝票に記入され,受注伝票ごとに一意な受注番号が採番されている。
設問1 次の表中の
に入れる正しい答えを,解答群の中から選べ。
受注表
|
受注番号 |
|
日付 |
受注明細表
|
受注番号 |
品番 |
|
顧客表
|
顧客番号 |
顧客名 |
商品表
|
品番 |
品名 |
単価 |
解答群
ア 金額 イ 顧客番号 ウ 顧客名
エ 数量 オ 品番 カ 品名
設問2 受注伝票ごとの受注額を確認するため,受注額表がビュー表として定義されている。これを利用して,次の情報を検索するための
SQL文を作成した。 SQL文の
に入れる正しい答えを,解答群の中から選べ。
“顧客あたりの平均受注額が受注額の平均より高額な顧客についての,顧客番号とその顧客の平均受注額”
受注額表
|
受注番号 |
日付 |
顧客番号 |
受注額 |
受注額:受注番号あたりの受注額
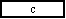 顧客番号, AVG(受注額) FROM
受注額表
顧客番号, AVG(受注額) FROM
受注額表
GROUP BY 顧客番号 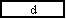 AVG(受注額) >
AVG(受注額) > 
解答群
ア CREATE VIEW イ EXISTS ウ HAVING
エ SELECT オ SUM(AVG(受注額)) カ SUM(受注額)
キ WHERE ク (SELECT AVG(受注額) FROM 受注額表)
問4 次のプログラムの説明,擬似言語の記述形式の説明及びプログラムを読んで,設問1,2に答えよ。
〔プログラムの説明〕
英数字及び記号からなる長さNの文字列を,編集して出力する副プログラム TextPrint である。
(1) 文字列は,Text[1],Text[2],… ,Text[N](N ≧ 1)の各要素に 1文字ずつ格納されている。
(2) 編集の仕様は,次のとおりである。
① ピリオド(“.”)で改行する。
② 指定した最大文字数(引数 Moji)で改行する。
③ 指定した最大行数(引数Gyo)で改ページする。
④ 指定した文字数(引数Yohaku)だけ,左側に余白を挿入する。
(3) TextPrint は,1行分の文字列を取り出す副プログラム GetLine ,編集結果の1ページ分の文字列を出力する副プログラム PageOut ,配列を空白文字で初期化する副プログラム ArrayInit を使用する。各副プログラムの引数の仕様を表1〜4に示す。
表1 TextPrint の引数
|
変数名 |
入力/出力 |
意 味 |
|
Text[] |
入力 |
出力対象である文字型の1次元配列 |
|
N |
入力 |
Text[]中の最後の文字の要素番号(N ≧ 1) |
|
Gyo |
入力 |
出力する1ページの最大行数(1 ≦ Gyo ≦ 50) |
|
Moji |
入力 |
出力する1行の最大文字数(Moji ≧ 1) |
|
Yohaku |
入力 |
左側の余白の文字数 |
表2 GetLine の引数
|
変数名 |
入力/出力 |
意 味 |
|
Text[] |
入力 |
出力対象である文字型の1次元配列 |
|
N |
入力 |
Text[]中の最後の文字の要素番号(N ≧ 1) |
|
Sp |
入力 |
開始位置 |
|
Moji |
入力 |
1 行の最大文字数 |
|
Ep |
出力 |
Text[Sp]から行末を探し,その位置を返す。
|
表3 PageOut の引数
|
変数名 |
入力/出力 |
意 味 |
|
Page[][] |
入出力 |
出力対象である文字型の2次元配列 |
|
Gyo |
入力 |
出力する行数 |
|
Retsu |
入力 |
出力する1行の文字数 |
表4 ArrayInit の引数
|
変数名 |
入力/出力 |
意 味 |
|
Page[][] |
入出力 |
初期化対象である文字型の 2 次元配列 |
|
Gyo |
入力 |
2 次元配列の最初の次元の要素数 |
|
Retsu |
入力 |
2 次元配列の 2 番目の次元の要素数 |
|
Value |
入力 |
初期化に用いる指定文字 |
〔擬似言語の記述形式の説明〕

〔プログラム〕
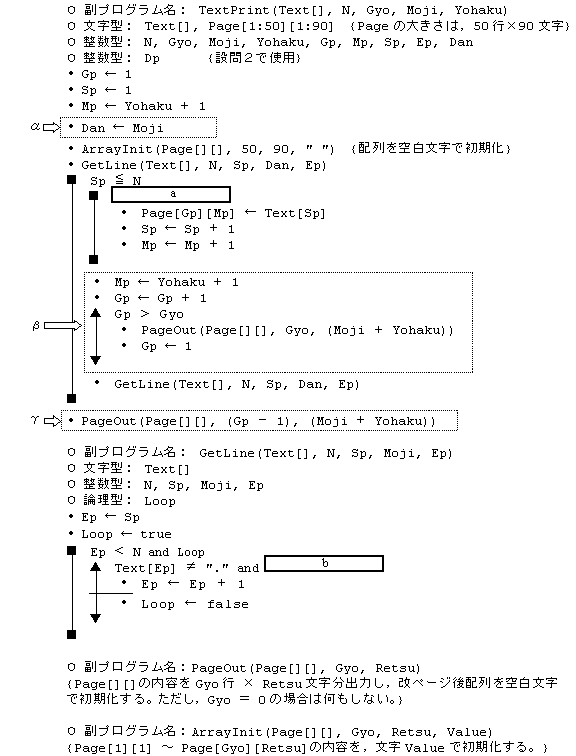
設問1 プログラム中の
に入れる正しい答えを,解答群の中から選べ。
解答群
ア Ep < (Sp + Dan) イ Ep < (Sp + Moji)
ウ Ep < (Sp + Moji − 1) エ Mp ≦ Ep
オ Mp < Ep カ Sp ≦ Ep
キ Sp < Ep
設問2 図のように,各ページを2段組で出力するようにプログラムの α , β , γ 部分を変更した。
1段目と2段目の間は2文字分空ける。変更部分中の に入れる正しい答えを,解答群の中から選べ。ここで,最大文字数(引数 Moji)の値は4以上の偶数とする。
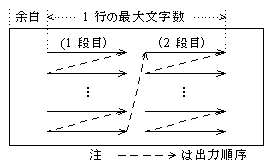
図 2段組のページ
〔変更部分〕
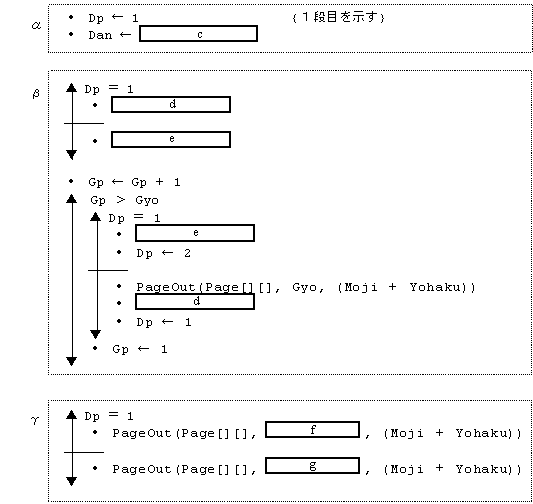
c に関する解答群
ア Moji / 2 イ (Moji − 2) / 2 ウ Moji / 2 − 2
d,e に関する解答群
ア Mp ← Yohaku イ Mp ← Yohaku + 1
ウ Mp ← Yohaku + Dan エ Mp ← Yohaku + Dan + 1
オ Mp ← Yohaku + Dan + 2 カ Mp ← Yohaku + Dan + 3
f,g に関する解答群
ア Gp イ Gp − 1 ウ Gyo エ Gyo − 1
問5 プログラム設計に関する次の記述を読んで,設問1〜3に答えよ。
在庫管理システムの一機能として,在庫データを照会するプログラムを作成する。
この在庫データ照会プログラムは,2種類のトランザクションを扱う。
トランザクション種別“A”は,指定した期間内の入出庫活動の照会であり,入出庫活動表を出力する。
トランザクション種別“S”は,現在の部品在庫量の照会であり,在庫状況表を出力する。最低在庫量を下回っている部品があるときは,該当部品を“赤”で示す。
トランザクションは,次に示す様式であり,各フィールドのけた数やデータ型などを検査する。また,在庫関連の表の利用認証を受けるため,利用許可番号をもたなければならない。トランザクションの利用許可番号が,利用許可番号表に存在するかどうかも検査する。これらの検査に合格しなかったトランザクションは,エラーとして処理する。
〔トランザクションの様式〕
(1) トランザクション種別“A”
|
|
トランザクション種別 |
期間開始年月日 |
期間終了年月日 |
|
部品番号の個数 |
部品番号 |
部品番号 |
… |
部品番号 |
(2) トランザクション種別“S”
|
|
トランザクション種別 |
|
部品番号の個数 |
部品番号 |
部品番号 |
… |
部品番号 |
〔在庫照会に関連するデータベースの様式の一部〕
(1) 部品表
|
部品番号 |
部品名称 |
発注単位 |
最低在庫量 |
(2) 在庫表
|
部品番号 |
在庫量 |
(3) 利用許可番号表
|
利用許可番号 |
(4) 入出庫表
|
部品番号 |
入出庫種別 |
個数 |
発生年月日時分 |
〔モジュール構造図〕
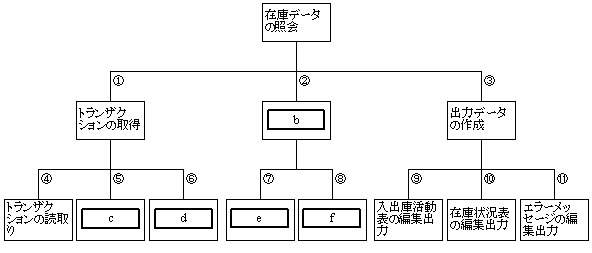
〔モジュール間インタフェース〕
|
インタフェース番号 |
入力 |
出力 |
|
① |
− |
トランザクション,様式検査フラグ,利用許可検査フラグ |
|
② |
トランザクション |
該当レコード,在庫不足フラグ,部品番号なしフラグ |
|
③ |
該当レコード, |
− |
|
④ |
− |
トランザクション |
|
⑤ |
利用許可番号 |
利用許可検査フラグ |
|
⑥ |
トランザクション |
様式検査フラグ |
|
⑦ |
トランザクション |
該当レコード(部品表,入出庫表),部品番号なしフラグ |
|
⑧ |
トランザクション |
該当レコード(部品表,在庫表),在庫不足フラグ,部品番号なしフラグ |
|
⑨ |
該当レコード(部品表,入出庫表) |
− |
|
⑩ |
該当レコード(部品表,在庫表),在庫不足フラグ |
− |
|
⑪ |
トランザクション, |
− |
〔フラグの様式〕
(1) 様式検査フラグ,利用許可検査フラグ
|
フラグ |
(合格:0,不合格:1)
(2) 在庫不足フラグ
|
部品番号の個数 |
フラグ |
フラグ |
… |
フラグ |
(トランザクション中の部品番号の順に,最低在庫量あり:0,在庫不足:1)
(3) 部品番号なしフラグ
|
部品番号の個数 |
フラグ |
フラグ |
… |
フラグ |
(トランザクション中の部品番号の順に,部品番号あり:0,部品番号なし:1)
設問1 トランザクションの様式中の に入れる正しい答えを,解答群の中から選べ。
a に関する解答群
ア “A” イ “AS”
ウ “S” エ トランザクションの個数
オ 入出庫種別 カ 年月日時分
キ フラグ ク 利用許可番号
設問2 モジュール構造図中の
に入れる正しい答えを,解答群の中から選べ。
b 〜 f に関する解答群
ア 該当レコードの取得 イ 在庫状況に関するレコードの処理
ウ 在庫表の更新 エ トランザクション様式の検査
オ 入出庫活動に関するレコードの処理 カ 入出庫表の更新
キ 発注メッセージの作成 ク 利用許可番号の検査
設問3 モジュール間インタフェース中の に入れる正しい答えを,解答群の中から選べ。
g に関する解答群
ア トランザクション イ トランザクション種別
ウ トランザクションの個数 エ 年月日時分
オ 部品番号 カ 部品番号の個数
キ 部品名称 ク 利用許可番号
ケ 利用許可番号表
h に関する解答群
ア 在庫不足フラグ,部品番号なしフラグ
イ 在庫不足フラグ,部品番号なしフラグ,様式検査フラグ
ウ 在庫不足フラグ,部品番号なしフラグ,利用許可検査フラグ
エ 在庫不足フラグ,様式検査フラグ
オ 在庫不足フラグ,様式検査フラグ,利用許可検査フラグ
カ 在庫不足フラグ,利用許可検査フラグ
キ 部品番号なしフラグ,様式検査フラグ
ク 部品番号なしフラグ,様式検査フラグ,利用許可検査フラグ
ケ 部品番号なしフラグ,利用許可検査フラグ
コ 様式検査フラグ,利用許可検査フラグ
問6 次のCプログラムの説明及びプログラムを読んで,設問に答えよ。
〔プログラムの説明〕
(1) 自然数 num(num≧2)を素因数に分解し,結果を次の例のように印字するプログラムである。
例1.自然数12を入力した場合
数値(2以上の自然数)を入力してください。 : 12
12 = 2 × 2 × 3
例2.自然数3を入力した場合
数値(2以上の自然数)を入力してください。 : 3
3 = 素数
(2) 素因数分解及び素数の判定手順は,次のとおりである。
① 変数 factor の値を2から始めて1ずつ増やしながら, num を factor で割った結果が factor 以上である間,②を実行する。
② num が factor で割り切れる場合,次の処理を num が factor で割り切れなくなるまで繰り返す。
(a) factor
の値を素因数として抽出する。
(b) num を factor で割った商を新たな num とする。
③ 最終的に割り切る factor がなかった場合には,num は素数であると判定する。
(3) このプログラムでは,(2) の手順① での繰返し処理の回数を減らすために,まず最初に自然数 num が2の倍数であるかどうかを判定する。 num が2の倍数の場合には,(2) の手順② によって,最初に2の因子をすべて抽出する。続いて,変数 factor の値を,3から始めて2ずつ増やしながら, num を factor で割った結果が factor 以上である間,素因数の抽出を繰り返す。
〔プログラム〕
(行番号)
1 #include <stdio.h>
2 #define TRUE 1
3 #define FALSE 0
4 main()
5 {
6 int num, prime = TRUE, factor = 2;
7 printf( "数値(2 以上の自然数)を入力してください。 : " );
8 scanf( "%d", &num );
9 printf( "%d =", num );
10 if ( num != factor )
11 while ( num % factor == 0 ) { /* 数値が 2 の倍数? */
12 if ( prime == FALSE ) printf( " ×" );
13 printf( " %d", factor );
14  ;
15 prime = FALSE;
16 }
17 factor++;
18 while (
;
15 prime = FALSE;
16 }
17 factor++;
18 while ( ) {
19 while ( num % factor == 0 ) {
20 if ( prime == FALSE ) printf( " ×" );
21 printf( " %d", factor );
22 ;
23 prime = FALSE;
24 }
25
) {
19 while ( num % factor == 0 ) {
20 if ( prime == FALSE ) printf( " ×" );
21 printf( " %d", factor );
22 ;
23 prime = FALSE;
24 }
25  ;
26 }
27 if ( prime == TRUE ) printf( " 素数¥n" );
28 else if ( num > 1 ) printf( " × %d¥n",
;
26 }
27 if ( prime == TRUE ) printf( " 素数¥n" );
28 else if ( num > 1 ) printf( " × %d¥n",  );
29 else printf( "¥n" );
30 }
);
29 else printf( "¥n" );
30 }
設問 プログラム中の
に入れる正しい答えを,解答群の中から選べ。
a,c に関する解答群
ア factor-- イ factor += 2 ウ num /= factor
エ num %= factor オ prime = FALSE カ prime = TRUE
b に関する解答群
ア num / factor >= factor イ num % factor != 0
ウ prime == FALSE エ prime == TRUE
d に関する解答群
ア factor イ num / factor
ウ num % factor エ num
オ prime
問7 次のCOBOLプログラムの説明及びプログラムを読んで,設問1,2に答えよ。
〔プログラムの説明〕
ユーザID の発行順に記録してある顧客情報ファイルを読み込んで,ユーザID をキー項目とした二分探索木を作成し,顧客リストとして出力するプログラムである。
顧客情報ファイル CUSTOM-IN のレコード様式は,次のとおりである。
|
ユーザ ID |
顧客情報 |
(1) 順ファイルである。
(2) ユーザID は乱数を利用して発行した12けたの英数字列であり,重複はない。
(3) レコードの順序は,ユーザID の発行順である。
(4) 顧客数は2,000以下である。
顧客リスト CUSTOM-OUT のレコード様式は,次のとおりである。
|
左ポインタ |
右ポインタ |
ユーザ ID |
顧客情報 |
(1) 順ファイルである。
(2) ユーザID が,“左側の子<親<右側の子”の規則で二分探索木を構成するようにレコードを記録する。
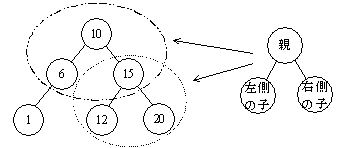
図1 二分探索木の例
(3) 左ポインタは,自身を親としたときの左側の子のレコードを指し,右ポインタは,右側の子のレコードを指す。
(4) 子をもたないときのポインタの値は,0とする。図1のレコードが,10,6,15,1,12,20 の順に記録されるときのポインタ及びユーザIDは次のようになる。
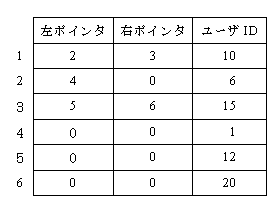
図2 ポインタ及びユーザID の例
〔プログラム〕
DATA DIVISION.
FILE SECTION.
FD CUSTOM-IN.
01 IN-R.
03 IN-ID PIC X(12).
03 IN-DATA PIC X(200).
FD CUSTOM-OUT.
01 OUT-R PIC X(220).
WORKING-STORAGE SECTION.
01 W-KENSU PIC 9(4) VALUE 0.
01 W-1 PIC 9(4).
01 W-2 PIC 9(4).
01 W-TABLE.
03 W-R OCCURS 2000.
05 POINT-L PIC 9(4).
05 POINT-R PIC 9(4).
05 W-ID PIC X(12).
05 W-DATA PIC X(200).
01 END-SW PIC X VALUE SPACE.
PROCEDURE DIVISION.
HAJIME.
OPEN INPUT CUSTOM-IN OUTPUT CUSTOM-OUT.
.
PERFORM UNTIL END-SW = "E"
READ CUSTOM-IN
AT END
MOVE "E" TO END-SW
NOT AT END
COMPUTE W-KENSU = W-KENSU + 1
MOVE IN-ID TO W-ID(W-KENSU)
MOVE IN-DATA TO W-DATA(W-KENSU)
IF W-KENSU > 1 THEN
MOVE 1 TO W-2
PERFORM UNTIL W-2 = 0
MOVE W-2 TO W-1
IF IN-ID > W-ID(W-1) THEN
MOVE POINT-R(W-1) TO W-2
ELSE
MOVE POINT-L(W-1) TO W-2
END-IF
END-PERFORM
IF IN-ID > W-ID(W-1) THEN
MOVE W-KENSU TO POINT-R(W-1)
ELSE
MOVE W-KENSU TO POINT-L(W-1)
END-IF
END-IF
END-READ
END-PERFORM.
PERFORM VARYING W-1 FROM 1 BY 1 UNTIL W-1 > W-KENSU
 END-PERFORM.
CLOSE CUSTOM-IN CUSTOM-OUT.
STOP RUN.
END-PERFORM.
CLOSE CUSTOM-IN CUSTOM-OUT.
STOP RUN.
設問1 プログラム中の
に入れる正しい答えを,解答群の中から選べ。
a に関する解答群
ア INITIALIZE W-TABLE イ MOVE SPACE TO W-TABLE
ウ MOVE 0 TO W-1 W-2
b に関する解答群
ア WRITE OUT-R イ WRITE OUT-R FROM IN-R
ウ WRITE OUT-R FROM W-R(W-1) エ WRITE OUT-R FROM W-R(W-KENSU)
設問2 顧客情報ファイルが次のとおりであった場合,このプログラムで出力される顧客リストを解答群の中から選べ。
|
CK66527C824W |
今井… |
|
K24U83458YZ4 |
鈴木… |
|
A35V2294QE78 |
高橋… |
|
JQ3526XNM445 |
小林… |
|
G87E99R32MK3 |
渡辺… |
|
SLB937RR244D |
加藤… |
|
BDD234L876XA |
田中… |
解答群
| ア |
|
イ |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ウ |
|
エ |
|
問8 次のJavaプログラムの説明及びプログラムを読んで,設問に答えよ。
〔プログラムの説明〕
ディジタル論理回路シミュレータを作成するためのクラスとテスト用クラスである。
(1) ゲートを表す抽象クラス Gate のサブクラスとして, NOT ゲートを表すクラス NotGate 及び ANDゲートを表すクラス AndGate を定義する。
(2) Gate のすべてのサブクラスは,メソッド connectOutputTo,getInput 及び getOutput を継承し,メソッド tick を実装する。
(3) メソッド connectOutputTo は,ゲートの出力信号線を,指定されたゲートの入力信号線に接続する。
(4) メソッド getInput 及び getOutput は,ゲートの入力信号線及び出力信号線をそれぞれ返す。
(5) メソッド tick は,各ゲート固有の演算を実行し,出力信号線に true 又は falseのいずれかの値を出力する。
(6) クラス Wire は,入力信号線又は出力信号線を表す。
(7) 各ゲートの出力信号線は,1本とする。
(8) テスト用クラス LogicCircuitTest で作成する回路及び動作の例を,次に示す。メソッド main は,演算結果の値を標準出力に表示する。
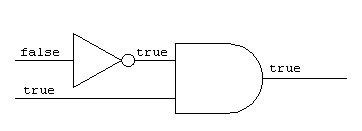
図 LogicCircuitTest で作成する回路及び動作の例
〔プログラム〕
class Wire {
private boolean value;
public boolean getValue() { return value; }
public void setValue(boolean value) { this.value = value; }
}
abstract class Gate {
protected Wire[] input;
protected Wire output;
public Gate(int nInputs) {
input = ;
for (int i = 0; i < nInputs; i++) { input[i] = new Wire(); }
output = new Wire();
}
public void connectOutputTo(Gate otherGate, int nthInput) {
try {
 ;
} catch (Exception e) {
e.printStackTrace();
}
}
public Wire getInput(int n) { return input[n]; }
public Wire getOutput() { return output; }
abstract public void tick();
}
class NotGate extends Gate {
public NotGate() { super(1); }
public void tick() { output.setValue(
;
} catch (Exception e) {
e.printStackTrace();
}
}
public Wire getInput(int n) { return input[n]; }
public Wire getOutput() { return output; }
abstract public void tick();
}
class NotGate extends Gate {
public NotGate() { super(1); }
public void tick() { output.setValue(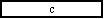 ); }
}
class AndGate extends Gate {
public AndGate() { super(2); }
public void tick() { output.setValue(
); }
}
class AndGate extends Gate {
public AndGate() { super(2); }
public void tick() { output.setValue(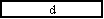 ); }
}
public class LogicCircuitTest {
public static void main(String[] args) {
Gate not = new NotGate();
Gate and = new AndGate();
not.connectOutputTo(and, 0);
not.getInput(0).setValue(false);
and.getInput(1).setValue(true);
not.tick();
and.tick();
System.out.println(and.getOutput().getValue());
}
}
); }
}
public class LogicCircuitTest {
public static void main(String[] args) {
Gate not = new NotGate();
Gate and = new AndGate();
not.connectOutputTo(and, 0);
not.getInput(0).setValue(false);
and.getInput(1).setValue(true);
not.tick();
and.tick();
System.out.println(and.getOutput().getValue());
}
}
設問 プログラム中の
に入れる正しい答えを,解答群の中から選べ。
a に関する解答群
ア new Wire(nInputs) イ new Wire[nInputs]
ウ new Wire() エ new Wire[] {new Wire()}
b に関する解答群
ア input[nthInput].setValue(otherGate.output.getValue())
イ input[nthInput] = otherGate.output
ウ otherGate.input[nthInput].setValue(output.getValue())
エ otherGate.input[nthInput] = output
c,d に関する解答群
ア input[0].getValue() || input[1].getValue()
イ !input[0].getValue() || !input[1].getValue()
ウ input[0].getValue() && input[1].getValue()
エ !input[0].getValue() && !input[1].getValue()
オ input[0].getValue() != input[1].getValue()
カ input[0].getValue()
キ !input[0].getValue()
ク 1 - input[0].getValue()
問9 次のアセンブラプログラムの説明及びプログラムを読んで,設問1〜3に答えよ。
〔プログラムの説明〕
副プログラム BINDECは,整数n(0 ≦ n ≦ 32767)を10進数の文字列として出力する。
(1) 整数nは,2進数としてGR1に格納されて,主プログラムから渡される。
(2) 表示文字列の長さは,5けたとする。
例えば,GR1の内容が 0000 0000 0110 1001 のとき,表示文字列は 00105 となる。
〔プログラム〕
(行番号)
1 BINDEC START ;
2 RPUSH ;
 3 LAD GR2,3 ; ループ回数
4 LAD GR4,0 ; バッファポインタ
5 LOOP1 LAD GR3,0 ; カウンタをゼロにする
6 LOOP2 CPA GR1,DIV,GR2 ;
7 ;
8 LAD GR3,1,GR3 ; カウンタに1 を加える
9 SUBA GR1,DIV,GR2 ;
10 JUMP LOOP2 ;
11 NEXTD OR GR3,='0' ; 数字の文字コードに変換
12 ST GR3,OUTB,GR4 ;
13 LAD GR4,1,GR4 ;
14 SUBA GR2,=1 ;
15 ;
16 JUMP LOOP1 ;
17 FIN OR GR1,='0' ;
18 ST GR1,OUTB,GR4 ;
19 OUT OUTB,LEN ;
20 RPOP ;
21 RET ;
22 DIV DC 10,100,1000,10000 ;
3 LAD GR2,3 ; ループ回数
4 LAD GR4,0 ; バッファポインタ
5 LOOP1 LAD GR3,0 ; カウンタをゼロにする
6 LOOP2 CPA GR1,DIV,GR2 ;
7 ;
8 LAD GR3,1,GR3 ; カウンタに1 を加える
9 SUBA GR1,DIV,GR2 ;
10 JUMP LOOP2 ;
11 NEXTD OR GR3,='0' ; 数字の文字コードに変換
12 ST GR3,OUTB,GR4 ;
13 LAD GR4,1,GR4 ;
14 SUBA GR2,=1 ;
15 ;
16 JUMP LOOP1 ;
17 FIN OR GR1,='0' ;
18 ST GR1,OUTB,GR4 ;
19 OUT OUTB,LEN ;
20 RPOP ;
21 RET ;
22 DIV DC 10,100,1000,10000 ;
 25 END ;
25 END ;
設問1 プログラム中の
に入れる正しい答えを,解答群の中から選べ。
解答群
ア JMI FIN イ JMI NEXTD ウ JNZ FIN
エ JNZ NEXTD オ JPL FIN カ JPL NEXTD
キ JUMP FIN ク JUMP NEXTD ケ JZE FIN
コ JZE NEXTD
設問2 nが#01A5のとき,行番号9のSUBA命令の実行回数として正しい答えを,解答群の中から選べ。
解答群
ア 3 イ 4 ウ 6 エ 7 オ 10
カ 11 キ 16 ク 42 ケ 420 コ 421
設問3 副プログラム BINDEC を, nが負の場合も扱えるようにする(−32767 ≦ n ≦32767)。
nが負のときは“-”を,そうでないときは“+”を,それぞれ文字列の最後に表示するように変更するため,プログラム中の α に命令群1 を挿入し,β を命令群2
と置き換えることにした。
命令群1の
に入れる正しい答えを,解答群の中から選べ。
命令群1 :α に挿入
| 命令群2 :β と置換え
|
解答群
ア ADDA GR1,GR3 イ ADDA GR3,GR1 ウ AND GR3,=#7FFF
エ SUBA GR1,GR3 オ SUBA GR3,GR1 カ XOR GR3,=#FFFF
問10 次のCプログラムの説明及びプログラムを読んで,設問1,2に答えよ。
〔プログラムの説明〕
画面上に凸四角形を描く関数 DrawRect を作成した。関数 DrawRect は,次の大域変数を参照して動作する。
int Vx[4], Vy[4]; /* 4 頂点の座標値配列(Vx は x 座標, Vy は y 座標) */
ただし,第1頂点P1 から第3頂点P3 までは,画面上で時計回りになっており,その座標値は順番に Vx と Vy に格納されている。画面上の座標系と原点の位置を図1に示す。
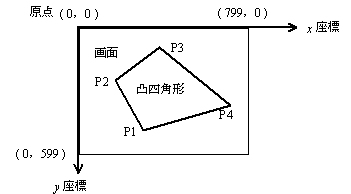
図1 画面上の座標系と原点の位置
第1頂点P1 から第4頂点P4 までは折れ線で結び,次に第4頂点P4 の位置を検査し,凸四角形になる場合にはP4 とP1 を結ぶ線分を描画して,返却値0を返す。 4頂点を結ぶ図形が,凸四角形ではなく,図2 に示すような図形となる場合には, P4 とP1 を結ぶ線分を描かずに,返却値−1 を返す。
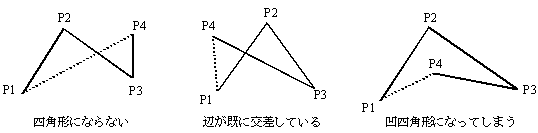
図2 凸四角形でない図形の例
なお,線分を引くために,次の二つの関数が用意されている。
void gMoveTo(int sx, int sy);
機能:線分の始点座標 (sx, sy) を設定する。この関数は描画を行わない。
void gLineTo(int ex, int ey);
機能:現在の始点から (ex, ey) まで線分を描き,次の描画のために始点を (ex, ey) に更新する。
〔プログラム〕
void gMoveTo(int, int);
void gLineTo(int, int);
int nCheck(double a)
{
if (a > 0.0) return 1;
else if (a < 0.0) return -1;
return 0;
}
int DrawRect( )
{
int nCnt;
double dx, dy, k;
int nSide0, nSide1, nSide2;
for (nCnt = 0; nCnt < 4; nCnt++) {
if (nCnt == 0) gMoveTo(Vx[nCnt], Vy[nCnt]);
else if (nCnt < 3) gLineTo(Vx[nCnt], Vy[nCnt]);
else {
gLineTo(Vx[nCnt], Vy[nCnt]);
/* P3 と P4 を通る直線の方程式を求める。 */
dx = Vx[3] - Vx[2];
dy = Vy[3] - Vy[2];
k = dx * Vy[2] - dy * Vx[2];
/* 第1の判定 */
nSide0 = nCheck(dy * Vx[0] - dx * Vy[0] + k);
nSide1 = nCheck(dy * Vx[1] - dx * Vy[1] + k);
if (nSide0 != nSide1) return -1;
/* P4 と P1 を通る直線の方程式を求める。 */
dx = Vx[0] - Vx[3];
dy = Vy[0] - Vy[3];
k = dx * Vy[3] - dy * Vx[3];
/* 第2の判定 */
nSide1 = nCheck(dy * Vx[1] - dx * Vy[1] + k);
nSide2 = nCheck(dy * Vx[2] - dx * Vy[2] + k);
if (nSide1 != nSide2) return -1;
/* P3 と P1 を通る直線の方程式を求める。 */
dx = Vx[0] - Vx[2];
dy = Vy[0] - Vy[2];
k = dx * Vy[2] - dy * Vx[2];
/* 第3の判定 */
nSide1 = nCheck(dy * Vx[1] - dx * Vy[1] + k);
nSide2 = nCheck(dy * Vx[3] - dx * Vy[3] + k);
if (nSide1 * nSide2 != -1) return -1;
}
}
gLineTo(Vx[0], Vy[0]);
return 0;
}
設問1 関数 DrawRect
は,描く図形が凸四角形かどうか調べるため,直線の方程式を利用して辺の交差を判定している。この処理に関する次の記述中の に入れる正しい答えを,解答群の中から選べ。ただし,L12は,第1頂点P1 と,第2頂点P2 を結ぶ線分を表す。
2 点 P3 (x3,y3),P4 (x4, y4) を通る直線の方程式を求める。この方程式は。 (x4 − x3)( y − y3) = (y4 − y3)( x − x3)
と表すことができる。 P4 と P3 の x 座標の差を dx, y 座標の差を dy とすると,。
dx = Vx[3] − Vx[2]
dy = Vy[3] − Vy[2]
である。この値を方程式に代入すると, dx( y − y3) = dy(x − x3)
となる。この式を展開すると,
dx × y − dx × y3 = dy × x − dy × x3
となる。ここで,定数をまとめて k とすると,直線の方程式は,
dy × x − dx × y + k = 0
と表すことができる。
定数 k は,x と y に の座標値を代入すれば求めることができるので,求める直線の方程式は, = 0 となる。
凸四角形になるためには,P3 と P4 を通る直線と,線分L12 が交差してはならない。この交差を判定するため, の x と y に,P1 と
P2 の座標値を代入し,計算結果の
を比較して判定する。
a,c に関する解答群
ア 第1頂点 P1 イ 第2頂点 P2 ウ 第3頂点 P3
エ 絶対値 オ 符号
b に関する解答群
ア dx × x ? dy × y + dx × Vy[2] ? dy × Vx[2]
イ dx × x ? dy × y + dy × Vy[2] ? dx × Vx[2]
ウ dy × x ? dx × y + dx × Vy[2] ? dy × Vx[2]
エ dy × x ? dx × y + dy × Vx[2] ? dx × Vy[2]
オ dy × x ? dx × y + dy × Vy[2] ? dx × Vx[2]
設問2 このプログラムは,描く図形が凸四角形になるかどうかを判定するため,三つの判定を順番に行っている。この判定のアルゴリズムに関する次の記述中の
に入れる正しい答えを,解答群の中から選べ。
(第1の判定)
 のような図形を無効にするため,
P3とP4を通る直線の方程式を求めて,P1とP2の位置を検査する。
のような図形を無効にするため,
P3とP4を通る直線の方程式を求めて,P1とP2の位置を検査する。
(第2の判定)
 や
や  のような図形を無効にするため,P4とP1を通る直線の方程式を求めて, P2とP3の位置を検査する。
のような図形を無効にするため,P4とP1を通る直線の方程式を求めて, P2とP3の位置を検査する。
(第3の判定)
 のような図形を無効にするため,
P3とP1を通る直線の方程式を求めて,P2とP4の位置を検査する。
のような図形を無効にするため,
P3とP1を通る直線の方程式を求めて,P2とP4の位置を検査する。
解答群
ア 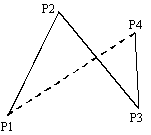 イ
イ 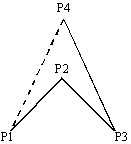
ウ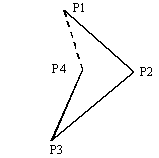 エ
エ 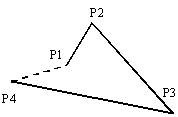
問11 次のCOBOLプログラムの説明及びプログラムを読んで,設問1,2に答えよ。
〔プログラムの説明〕
企業の売上高などを記録した企業統計ファイルがある。企業統計ファイルのレコードを,各項目ごとにコンマで区切った CSV(Comma Separated Value)形式に変換して,企業統計 CSV ファイルに出力するプログラムである。レコードの各項目は,項目ごとに指定された方法で変換する。
(1) 企業統計ファイルのレコード様式は,次のとおりである。
|
企業コード6 けた |
社 名 |
売上高 |
営業利益 |
経常利益 |
① 企業コードは,6 けたの英数字項目である。
② 売上高,営業利益及び経常利益は,数字項目である。数字は,右詰めで,8 けた未満の場合は,上位のけたに 0 が埋められている。
③ 社名は 1 文字以上の英字,数字,空白及びピリオドで構成され,コンマは含まない。社名は左詰めで,その文字列が項目の文字数に満たないところは,空白が埋められている。なお,空白だけからなる社名はない。
(2) 企業統計 CSV ファイルのレコード様式は,次のとおりである。
|
企業コード,社名,売上高,営業利益,経常利益 |
① 項目と項目の区切りには,半角コンマを用いる。
② このファイルのレコードは,可変長とする。
(3) 企業統計ファイルのデータ変換方法は,次のとおりである。
① 企業コードは,変換しない。
② 社名については,その文字列の末尾の連続する空白は削除する。
③ 売上高,営業利益及び経常利益については,先頭の一つ又は連続する0 は削除する。ただし,これらの項目の全けたがゼロの場合は,1けたの 0 とする。
〔プログラム〕
(行番号)1 DATA DIVISION. 2 FILE SECTION. 3 FD COMPANY-FILE. 4 01 COMPANY-REC. 5 02 COMP-CODE PIC X(06). 6 02 COMP-NAME OCCURS 50 PIC X(01). 7 02 COMP-SUM OCCURS 3 PIC 9(08). 8 FD CSV-FILE 9 RECORD IS VARYING IN SIZE 10 FROM 14 TO 84 DEPENDING ON P-CNT. 11 01 CSV-REC PIC X(84). 12 WORKING-STORAGE SECTION. 13 01 EOF-FLG PIC X(01) VALUE SPACE. 14 01 OUT-WRK. 15 02 OUT-S-WRK OCCURS 84 PIC X(01). 16 01 NUM-WRK. 17 02 NUM9-WRK PIC 9(08). 18 02 REDEFINES NUM9-WRK. 19 03 NUMX-WRK OCCURS 8 PIC X(01). 20 01 L-CNT PIC 9(02). 21 01 M-CNT PIC 9(02). 22 01 P-CNT PIC 9(02). 23 01 V-CNT PIC 9(01). 24 01 W-CNT PIC 9(02). 25 01 SEPARATOR-CHAR PIC X(01) VALUE ",". 26 PROCEDURE DIVISION. 27 PROC-RTN. 28 OPEN INPUT COMPANY-FILE OUTPUT CSV-FILE. 29 PERFORM UNTIL EOF-FLG = "E" 30 READ COMPANY-FILE AT END 31 MOVE "E" TO EOF-FLG 32 NOT AT END 33 PERFORM MOVE-RTN 34 END-READ 35 END-PERFORM. 36 CLOSE COMPANY-FILE CSV-FILE. 37 STOP RUN. 38 MOVE-RTN. 39 MOVE COMP-CODE TO OUT-WRK. 40 MOVE SEPARATOR-CHAR TO OUT-S-WRK (7). 41 MOVE 7 TO P-CNT. 42 PERFORM VARYING L-CNT FROM 50 BY -1 UNTIL L-CNT < 2 43 OR COMP-NAME (L-CNT) NOT = SPACE 44 CONTINUE 45 END-PERFORM. 46 PERFORM VARYING W-CNT FROM 1 BY 1 UNTIL 47 COMPUTE P-CNT = P-CNT + 1 48 MOVE COMP-NAME (
63 COMPUTE P-CNT = P-CNT + 1 64 MOVE NUMX-WRK (M-CNT) TO OUT-S-WRK (P-CNT) 65 END-PERFORM.
設問1 プログラム中の
に入れる正しい答えを,解答群の中から選べ。
a に関する解答群
ア W-CNT < 1 イ W-CNT > 8 ウ W-CNT > 50
エ W-CNT > L-CNT オ W-CNT < L-CNT カ W-CNT > M-CNT
キ W-CNT < M-CNT ク W-CNT > P-CNT ケ W-CNT < P-CNT
b,c に関する解答群
ア L-CNT イ M-CNT ウ P-CNT エ V-CNT
オ W-CNT
d に関する解答群
ア L-CNT BY 1 UNTIL M-CNT > 7 イ L-CNT BY 1 UNTIL M-CNT > 8
ウ P-CNT BY 1 UNTIL M-CNT > 7 エ P-CNT BY 1 UNTIL M-CNT > 8
オ W-CNT BY 1 UNTIL M-CNT > 7 カ W-CNT BY 1 UNTIL M-CNT > 8
キ V-CNT BY 1 UNTIL M-CNT > 7 ク V-CNT BY 1 UNTIL M-CNT > 8
設問2 次の記述中の
に入れる正しい答えを,解答群の中から選べ。
金額が入る項目(売上高,営業利益及び経常利益)が負になった場合に対応させることになった。金額が入る項目が負の場合は,項目の左端に“-”が付加されるように,次のとおりプログラムを変更する。
|
処置 |
プログラムの変更内容 |
|
行番号7 を置換 |
02 COMP-SUM OCCURS 3 PIC S9(08). |
|
行番号9〜11を置換 |
RECORD IS VARYING IN SIZE
FROM 14 TO 87 DEPENDING ON P-CNT.
01 CSV-REC PIC X(87). |
|
行番号15 を置換 |
02 OUT-S-WRK OCCURS 87 PIC X(01). |
|
行番号 |
IF |
e に関する解答群
ア 49 イ 53 ウ 54 エ 56 オ 65
f に関する解答群
ア NUM9-WRK < 0 イ NUM9-WRK > 0
ウ COMP-SUM (L-CNT) < 0 エ COMP-SUM (L-CNT) > 0
オ COMP-SUM (M-CNT) < 0 カ COMP-SUM (M-CNT) > 0
キ COMP-SUM (V-CNT) < 0 ク COMP-SUM (V-CNT) > 0
問12 次のJavaプログラムの説明及びプログラムを読んで,設問に答えよ。
〔プログラムの説明〕
プログラム1は,コンマ区切り(CSV形式)のデータを解析するための汎用クラス CSVParser である。プログラム2は,クラス CSVParser を拡張して,コンマ区切り形式の入力データファイルをタグ付き形式の出力データに変換するプログラムである。
クラス CSVParser は,コンストラクタに指定されたコンマ区切りのデータファイルをメソッド parse で解析し,次に示す状態に応じて各メソッドを呼び出す。
|
状態 |
呼び出されるメソッド |
引数 |
|
ファイルの読込みを開始した |
startDocument |
なし |
|
新しいレコードに達した |
startRecord |
n:レコード番号 |
|
レコード中のフィールドを |
value |
chars:フィールドの値 |
|
レコードの終端に達した |
endRecord |
n:レコード番号 |
|
ファイルの処理を完了した |
endDocument |
なし |
プログラム2の入力データファイル test.csv と出力結果を,それぞれ図1及び
図2に示す。
Ichiro Tanaka,tanaka@sales.example.com,111-1111 |
<addressbook>
<person id="1">
<name>Ichiro Tanaka</name>
<email>tanaka@sales.example.com</email>
<phone>111-1111</phone>
</person>
<person id="2">
<name>Jiro Yamada</name>
<email>yamada@eng.example.com</email>
<phone>222-2222</phone>
</person>
<person id="3">
<name>Saburo Suzuki</name>
<email>suzuki@mkt.example.com</email>
<phone>333-3333</phone>
</person>
</addressbook> |
入力データの形式は次のとおりである。
(1) 1レコードは,三つの項目からなり,各項目はコンマ(“,”)で区切られている。レコードの終端には改行文字がある。
(2) 項目には,氏名,電子メールアドレス及び電話番号があり, 1レコード中にこれらの項目が 1個ずつ,この順に並ぶ。
① 項目にコンマが含まれることはない。
② 項目は省略できず,空白文字だけからなる項目はない。
出力データの形式は次のとおりである。
(1) 値を開始タグと終了タグとで囲んだデータの単位を,要素と呼ぶ。
① 開始タグは <タグ名> と記述し,終了タグは </タグ名> と記述する。
② 開始タグには,<タグ名 属性名="属性値"> という形式で,属性を記述できる。
③ 以降の説明では,この要素のことを,“要素 タグ名”と呼ぶ。
(2) 要素は入れ子にすることができる。すなわち,ある要素の中に他の要素を入れることができる。
(3) すべての開始タグと終了タグとは,対応がとれている必要がある。すなわち,ある開始タグで始まる要素は,同じタグ名をもつ終了タグによって閉じる。
入力データ形式から出力データ形式への変換手順は,次のとおりである。
(1) 入力データ全体をまとめて,要素 addressbook を作成する。
(2) 入力データの 1レコードごとに,要素 person を作成する。要素 person には,レコードを読み込んだ順番を属性id の値として付加する。
(3) 1レコード中の各項目から,レコード中での項目の出現の順に,name, email 及び phone の各要素をそれぞれ作成する。
テキストファイルの内容を読み込むのに,クラス java.io.FileReader を用いる。動作は次のとおりである。
(1) コンストラクタにファイル名を示す文字列を与えると,当該ファイルからの入力ストリームを開く。
(2) メソッド read は,入力ストリームから1文字を読み込んで int 型として返す。
(3) 入力ストリームの末尾に達した時点でメソッド read を呼び出すと,−1を返す。
〔プログラム 1〕
import java.io.FileReader;
import java.io.IOException;
import java.io.FileNotFoundException;
public class CSVParser {
private FileReader reader;
public CSVParser(String fileName) throws FileNotFoundException {
// テキスト入力ファイル用の reader を生成する。
reader = new FileReader(fileName);
}
public void startDocument() {}
public void startRecord(int n) {}
 public void endRecord(int n) {}
public void endDocument() {}
public void parse() throws IOException {
int c;
StringBuffer buf = new StringBuffer();
boolean
public void endRecord(int n) {}
public void endDocument() {}
public void parse() throws IOException {
int c;
StringBuffer buf = new StringBuffer();
boolean  ;
int fieldNumber = 0;
int recordNumber = 0;
startDocument();
while ((c = reader.read()) != -1) { // reader から1文字読み込む。
// メソッド read は入力ストリームに利用可能な文字がない場合-1を返す。
char ch = (char)c;
switch (ch) {
case ',':
;
int fieldNumber = 0;
int recordNumber = 0;
startDocument();
while ((c = reader.read()) != -1) { // reader から1文字読み込む。
// メソッド read は入力ストリームに利用可能な文字がない場合-1を返す。
char ch = (char)c;
switch (ch) {
case ',':
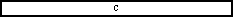 ;
buf.delete(0, buf.length());
break;
case '¥n':
if (!endOfRecord) {
endOfRecord = true;
;
buf.delete(0, buf.length());
fieldNumber = 0;
;
buf.delete(0, buf.length());
break;
case '¥n':
if (!endOfRecord) {
endOfRecord = true;
;
buf.delete(0, buf.length());
fieldNumber = 0;
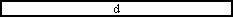 ;
}
break;
default:
if (endOfRecord) {
;
}
break;
default:
if (endOfRecord) {
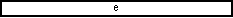 ;
}
endOfRecord = false;
;
}
endOfRecord = false;
 ;
}
}
endDocument();
}
}
;
}
}
endDocument();
}
}〔プログラム 2〕
import java.io.FileNotFoundException;
public class TaggedDataGenerator extends CSVParser {
public TaggedDataGenerator(String fileName)
throws FileNotFoundException {
super(fileName);
}
public void startDocument() {
System.out.println("<addressbook>");
}
public void startRecord(int n) {
System.out.println("¥t<person id=¥""+n+"¥">");
}
public void value(String chars, int n) {
String tag = (n == 1) ? "name" : (n == 2) ? "email" : "phone";
System.out.println("¥t¥t<"+tag+">"+chars+"</"+tag+">");
}
public void endRecord(int n) {
System.out.println("¥t</person>");
}
public void endDocument() {
System.out.println("</addressbook>");
}
public static void main(String [] args) {
TaggedDataGenerator parser = null;
try {
parser = new TaggedDataGenerator("test.csv");
parser.parse();
} catch (Exception e) {
e.printStackTrace();
}
}
}
設問 プログラム中の
に入れる正しい答えを,解答群の中から選べ。
a に関する解答群
ア public void value(StringBuffer chars, int n) {}
イ public void value(String chars, int n) {}
ウ abstract public void value(String chars, int n) {}
エ public void value(String chars, int n);
b に関する解答群
ア endOfRecord = null イ endOfRecord = false
ウ endOfRecord = true エ endOfRecord
c に関する解答群
ア value(buf, fieldNumber)
イ value(buf.toString(), fieldNumber)
ウ value(buf, ++fieldNumber)
エ value(buf.toString(), ++fieldNumber)
d,e に関する解答群
ア startDocument()
イ startDocument(++recordNumber)
ウ startRecord(recordNumber)
エ startRecord(++recordNumber)
オ endDocument()
カ endDocument(recordNumber)
キ endRecord()
ク endRecord(recordNumber)
f に関する解答群
ア buf += ch イ buf[buf.length] = ch
ウ buf.append(ch) エ buf.append(ch.toString())
問13 次のアセンブラプログラムの説明及びプログラムを読んで,設問1〜5に答えよ。
〔プログラムの説明〕
除算を行う副プログラム DIVIDE である。
(1) GR1 に被除数,GR2 に除数が格納されて,主プログラムから渡される。被除数,除数ともに符号なしの正の整数(1〜32767)とする。
(2) 副プログラム DIVIDE は,GR3に商,GR0に剰余を設定して,主プログラムに戻る。
(3) 副プログラム DIVIDE の実行において,GR1の内容は保存されない。
〔プログラム〕
(行番号)
1 DIVIDE START
2 LAD GR3,0
3 L1 CPL GR1,GR2
4 JMI FIN
5

6 LAD GR3,1,GR3
7 JUMP L1
8 FIN LD GR0,GR1
9 RET
10 END
設問1 プログラム中の
に入れる正しい答えを,解答群の中から選べ。
解答群
ア ADDL GR1,GR2 イ ADDL GR2,GR3
ウ SLL GR1,0,GR3 エ SLL GR2,0,GR3
オ SUBL GR1,GR2 カ SUBL GR2,GR3
設問2 GR1に32,GR2に1 を格納して主プログラムから呼び出したとき,行番号 3の命令を実行する回数として正しい答えを,解答群の中から選べ。
解答群
ア 30 イ 31 ウ 32 エ 33 オ 34
設問3 元のプログラムと異なるアルゴリズムによって除算を行う副プログラム DIVIDE2 を,新たに作成した。プログラム中の
に入れる正しい答えを,解答群の中から選べ。このプログラムの動作は,次のとおりである。
(1) 除数を倍々にしてゆき,被除数以下で最大の値 m(除数×2n)を求め,このときの 2n を商に加える。
(2) 被除数から mを引いたものを新しい被除数とする。
(3) 新しい被除数 < 除数となるまで (1),(2) を繰り返す。繰返しが終了したときの被除数が,剰余となる。
ここで,副プログラム DIVIDE2 の実行において,GR1,GR4 及び GR5 の内容は保存されない。
(行番号)
1 DIVIDE2 START
2 LAD GR3,0
3 L1 LAD GR5,1
4

5 L2 CPL GR1,GR4 ; 被除数 <(除数×2n)?
6 JMI ADJ
7 SLL GR5,1 ; GR5 ← 2n
8 SLL GR4,1 ; GR4 ← 除数×2n
9 JUMP L2
10 ADJ SRL GR5,1
11 JZE FIN
12 SRL GR4,1 ; GR4 ← m
13 ADDL GR3,GR5
14
; 新しい被除数を設定
15 JUMP L1
16 FIN LD GR0,GR1
17 RET
18 END
a に関する解答群
ア LD GR2,GR4 イ LD GR4,GR2 ウ SLL GR1,0,GR4
エ SUBL GR1,GR2 オ SUBL GR1,GR4
b に関する解答群
ア LD GR1,GR4 イ LD GR4,GR1 ウ SLL GR1,0,GR4
エ SUBL GR1,GR2 オ SUBL GR1,GR4
設問4 設問3の DIVIDE2 を,GR1に32,GR2に1を格納して主プログラムから呼び出したとき,行番号10の命令を最初に実行する直前の GR4 の値として正しい答えを,解答群の中から選べ。
解答群
ア 16 イ 32 ウ 48 エ 64 オ 128
設問5 GR1に32,GR2に1を格納して主プログラムから呼び出したとき,元のプログラム DIVIDE と設問3の DIVIDE2 の実行される命令数の差に最も近い値を,解答群の中から選べ。
解答群
ア 70 イ 85 ウ 100 エ 115 オ 130
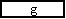 ,在庫不足フラグ,部品番号なしフラグ,様式検査フラグ,利用許可検査フラグ
,在庫不足フラグ,部品番号なしフラグ,様式検査フラグ,利用許可検査フラグ
 CONT ST GR2,SIGN
CONT ST GR2,SIGN の後に追加
の後に追加 THEN
THEN